Datos que cuentan historias. Ideas que generan impacto.
Hola, Soy Roberto Bravo
Cientifico de Datos
Ingeniero de Software
Amante de los libros
Con alma de narrador, transformo datos en ideas estratégicas y café en soluciones. Este sitio es mi bitácora personal, donde los algoritmos se cruzan con la intuición y la curiosidad no tiene techo.

Algo sobre mi
Ciencia de Datos
Uso técnicas estadísticas, aprendizaje automático y análisis exploratorio para encontrar patrones y responder preguntas de negocio con evidencia y precisión.
Inteligencia de Negocios
Diseño dashboards, modelos de KPI y reportes automatizados para mejorar la toma de decisiones estratégicas en entornos corporativos.
Ingeniería de Datos
Organizo el caos, creo pipelines de datos eficientes, gestiono bases de datos relacionales y no relacionales, y aseguro que la información fluya limpia y ordenada donde debe estar.
Código con propósito.
Desarrollo soluciones web y herramientas personalizadas que conectan datos, usuarios y objetivos, con un enfoque funcional y escalable.
Estrategia y Negocios
La visión detrás del análisis en la que combino datos con criterio de negocio para diseñar estrategias de impacto. Desde campañas de marketing hasta optimización operativa, siempre con foco en resultados.
Curiosidad estructurada.
Me fascina pensar en voz alta. Investigo, escribo y comparto ideas sobre ciencia, tecnología y sociedad, buscando siempre esa chispa que despierta nuevas preguntas.
Mi CV
Educacion
Maestria en Business Intelligence & Big Data
EUDE Business School(2024 - 2025)Formación especializada en análisis predictivo, visualización avanzada, modelado de datos y procesamiento de grandes volúmenes de información. Enfoque práctico en herramientas como SQL, Python, Power BI, Hadoop y Spark para impulsar la toma de decisiones basada en datos.
MBA en Dirección Ejecutiva de Nagocios
Fomato Educativo Escuela de Negocios - Universidad de Cadiz (2023- 2024)Formación orientada a liderazgo estratégico, gestión de alto nivel y toma de decisiones en entornos complejos. Enfoque en finanzas, marketing, innovación, desarrollo organizacional y dirección de proyectos con visión integral del negocio.
Maestria en informática Empresarial
Universidad de Managua (2011-2012)Especialización en el diseño e implementación de soluciones tecnológicas aplicadas a procesos empresariales. Formación en sistemas de información, transformación digital, arquitectura empresarial y alineación estratégica entre tecnología y negocio.
Postgrado en Bases de Datos Avanzadas
Universidad de Managua (2012)Especialización en diseño, administración y optimización de bases de datos relacionales y no relacionales. Formación en modelado avanzado, tuning de consultas, seguridad de datos y tecnologías como SQL Server, Oracle, MongoDB y Big Data.
Postgrado en ingeniería de software
Universidad de Managua (2012)Formación avanzada en diseño, desarrollo y mantenimiento de sistemas de software. Enfoque en metodologías ágiles, arquitectura de software, gestión de proyectos y aseguramiento de calidad para construir soluciones robustas y escalables.
Postgrado en Sistemas ERP
Universidad de Managua (2011)Especialización en planificación y gestión empresarial mediante sistemas integrados. Formación práctica en módulos clave de ERP (finanzas, logística, RRHH) y en la implementación y optimización de soluciones como SAP y similares para mejorar la eficiencia operativa.
Ingeniería en Computación
Universidad de Managua (2006-2010)Formación sólida en desarrollo de software, estructuras de datos, bases de datos, redes y sistemas operativos. Enfoque práctico en resolución de problemas computacionales, programación y diseño de soluciones tecnológicas escalables.
Experiencia Laboral
Sr Business Intelligence Analyst
Banco de Finanzas (2022 - Presente)Desarrollo análisis de datos para apoyar decisiones estratégicas mediante ciencia de datos, análisis predictivo y big data. Creo modelos de machine learning, visualizo información con Power BI y Tableau, y gestiono grandes volúmenes de datos con tecnologías como Hadoop y Spark. Mi enfoque está en generar insights accionables que mejoren la eficiencia y el crecimiento del negocio.
Business Intelligence Specialist
Banco LAFISE (2020-2022)Diseño modelos de datos y dashboards interactivos en herramientas como Google Data Studio y Amazon QuickSight. Realizo perfilamiento de clientes aplicando técnicas de machine learning, gestiono Data Lakes en entornos AWS y automatizo flujos de carga de datos, incluyendo el monitoreo continuo de su calidad para garantizar información confiable y oportuna.
Business Intelligence Specialist
Telefonica (2026 -2019)Modelación y desarrollo de bases de datos multidimencionales, para la generación de reportes dinámicos de indicadores comerciales de ventas, ingresos, recargas y facturación. Desarrollo de plataformas digital para la gestión de información comercial (catalogo de vendedores, rutas, zona,supervisores, jefes y gerentes comerciales). Desarrollo de aplicativos web en LAMP Stack para disponibilización de información comercial para diferentes áreas del negocio. Desarrollo de procesos automáticos para campañas, reportes y análisis con SSIS. Optimización de procesos heredados con mejora de rendimiento y disponibilidad de la información. Visualización de datos para la toma de decisiones estratégicas por medio de Power BI.
Especialista de Desarrollo de Software
Yota (2012-2015)Diseño e implementación de aplicaciones empresariales, incluyendo sistemas CRM y ERP. He desarrollado soluciones web tanto en frontend como backend, combinando diseño atractivo con funcionalidad eficiente para crear plataformas robustas y orientadas al usuario.
Data Skills
SQL
MySQL
Postgresql
Oracle
Athenas AWS
Code Skills
Python
Golang
JAVASCRIPT
PHP
HTML
Transformación Digital
Certificación centrada en el diseño e implementación de estrategias digitales que impulsen la innovación y la competitividad empresarial. Aborda el uso de tecnologías emergentes, cambio cultural, liderazgo digital y rediseño de procesos para adaptarse a entornos dinámicos y orientados al dato.
AWS Cloud Practitioner
Certificación que valida conocimientos fundamentales sobre servicios en la nube de AWS, incluyendo arquitectura básica, modelos de facturación, seguridad y buenas prácticas. Acredita la capacidad para comprender el valor de la nube en contextos empresariales y tomar decisiones informadas sobre soluciones basadas en AWS.
Decision Making
Harvard ManageMentorCertificación orientada al desarrollo de habilidades para analizar situaciones complejas, evaluar alternativas y tomar decisiones eficaces en contextos empresariales. Basada en metodologías de Harvard Business Publishing, integra pensamiento crítico, gestión del riesgo y alineación estratégica.
Cloud Digital Leader – Google
Certificación que acredita conocimientos esenciales sobre los productos, servicios y capacidades de Google Cloud. Enfocada en el impacto de la computación en la nube en la transformación digital, permite identificar oportunidades de negocio, tomar decisiones estratégicas y evaluar soluciones en entornos cloud.
Business Model Canvas
Certificación enfocada en el diseño y análisis de modelos de negocio mediante el uso del lienzo de modelo de negocio (Business Model Canvas). Desarrolla habilidades para visualizar, estructurar y validar propuestas de valor, segmentos de clientes, flujos de ingresos y recursos clave de forma ágil y estratégica.
Azure Fundamentals (AZ-900)
Certificación que demuestra comprensión básica de los servicios en la nube y cómo se ofrecen con Microsoft Azure. Cubre conceptos clave como cómputo, almacenamiento, redes, seguridad, modelos de precios y soporte en Azure, brindando una base sólida para trabajar con soluciones en la nube dentro del ecosistema Microsoft.
Scrum Master
Certificación que valida competencias en la aplicación del marco ágil Scrum para la gestión de proyectos. Acredita conocimientos en roles, eventos y artefactos de Scrum, facilitando equipos de trabajo colaborativos, adaptativos y enfocados en la entrega continua de valor.
Company Experience
Personal Portfolio April Fools
University of DVI (1997 - 2001))The education should be very interactual. Ut tincidunt est ac dolor aliquam sodales. Phasellus sed mauris hendrerit, laoreet sem in, lobortis mauris hendrerit ante.
Examples Of Personal Portfolio
University of DVI (1997 - 2001))The education should be very interactual. Ut tincidunt est ac dolor aliquam sodales. Phasellus sed mauris hendrerit, laoreet sem in, lobortis mauris hendrerit ante.
Tips For Personal Portfolio
University of DVI (1997 - 2001))The education should be very interactual. Ut tincidunt est ac dolor aliquam sodales. Phasellus sed mauris hendrerit, laoreet sem in, lobortis mauris hendrerit ante.
Job Experience
Personal Portfolio April Fools
University of DVI (1997 - 2001))The education should be very interactual. Ut tincidunt est ac dolor aliquam sodales. Phasellus sed mauris hendrerit, laoreet sem in, lobortis mauris hendrerit ante.
Examples Of Personal Portfolio
University of DVI (1997 - 2001))The education should be very interactual. Ut tincidunt est ac dolor aliquam sodales. Phasellus sed mauris hendrerit, laoreet sem in, lobortis mauris hendrerit ante.
Tips For Personal Portfolio
University of DVI (1997 - 2001))The education should be very interactual. Ut tincidunt est ac dolor aliquam sodales. Phasellus sed mauris hendrerit, laoreet sem in, lobortis mauris hendrerit ante.
Mi Blog


Parte II: Más Allá de la Atención — El Pensamiento Emergente de las IAs
Cada vez que alguien me pregunta cómo funcionan modelos como ChatGPT, siento que detrás de una respuesta simple hay un universo entero de procesos matemáticos, lingüísticos y computacionales. Quiero contarte, de forma amena pero rigurosa, cómo funcionan los llamados Grandes Modelos de Lenguaje (LLM), y por qué han revolucionado la forma en que conectamos con la inteligencia artificial.
¿Qué es un LLM y qué lo hace tan especial?
Los LLM son modelos de inteligencia artificial entrenados con enormes cantidades de texto para comprender y generar lenguaje natural. Modelos como GPT-4, Claude o Gemini han sido entrenados con billones de palabras, absorbiendo patrones, estilos, gramática y hechos. Pero más allá del tamaño este proceso no ocurre de forma mágica: hay un flujo estructurado de procesamiento que va desde el texto en crudo hasta su representación matemática y su posterior interpretación mediante redes neuronales.
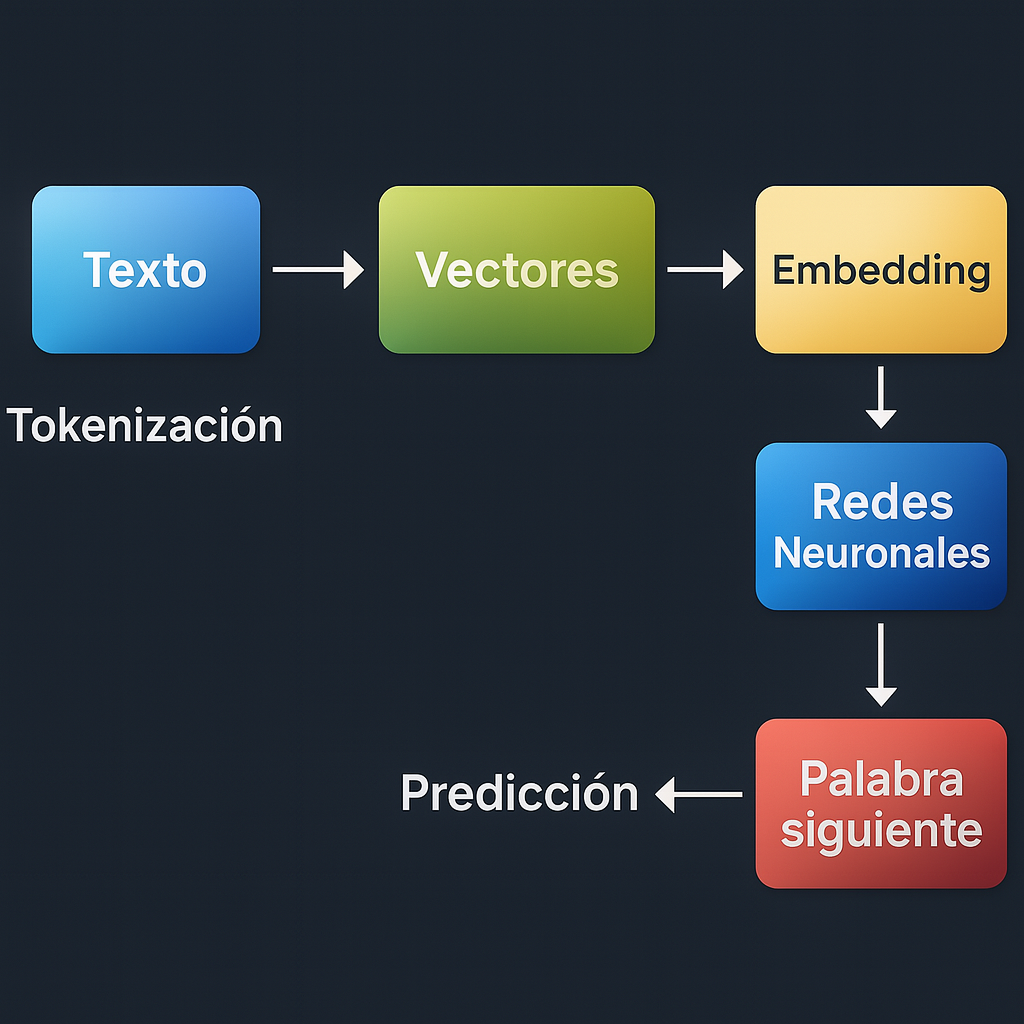
1- Tokenización: partir el lenguaje en fragmentos comprensibles
El primer paso para que una máquina entienda el lenguaje es dividir el texto en tokens, que pueden ser palabras, subpalabras o incluso sílabas. Esto permite que el modelo procese frases complejas como una secuencia ordenada de fragmentos reconocibles.
Ejemplo simple:
Texto: “Hola mundo”
Tokenización por palabras: [“Hola”, “mundo”]
Tokenización por subpalabras (BPE): [“Ho”, “la”, “mun”, “do”]
Los LLM como GPT usan tokenizadores basados en algoritmos como Byte Pair Encoding (BPE) o SentencePiece para dividir el texto en fragmentos reutilizables. Esto permite manejar vocabularios más pequeños y representar de manera eficiente palabras raras o compuestas.
2-Vectorización y Embeddings
Una vez que el texto se convierte en tokens, estos deben representarse de forma numérica para que una máquina pueda procesarlos. Esta representación se llama vectorización. Existen varias formas de hacer esto, una de ellas es One-hot encoding: Consiste en representar cada token como un vector con un único 1 en la posición correspondiente al token en el vocabulario, y 0 en las demás.
Sin embargo esto lleva a algunos problemas:
Escalabilidad: Si el vocabulario tiene 50,000 tokens, cada vector tendrá 50,000 dimensiones lo que incrementa la complejidad computacional de forma exponencial.
Semántica: Este metodo complica mucho la creacion de semantica, lo que implica crear conexiones logicas entre las palabras.
Esto lleva a la necesidad de representaciones más densas y semánticamente informativas: los embeddings.
A este punto todo se va poniendo un poco mas movido. Empecemos por las definiciones: los embeddings son vectores densos y continuos que representan tokens en un espacio de menor dimensión, donde la proximidad entre vectores refleja similitud semántica, que significa esto? pues que los vectores con mayor cercania representan palabras con un significado asociado mas profundo, gracias a esto el modelo puede entender que ‘rey’ y ‘reina’ están más cerca entre sí que ‘rey’ y ‘silla’.
Los embeddings se entrenan junto con el modelo. Inicialmente se asignan aleatoriamente y, a medida que el modelo aprende, se ajustan para que reflejen el contexto y significado de los tokens.
Cuales son las ventajas del uso de embeddings?
1-Capturan relaciones sintácticas y semánticas.
2-Permiten generalización: palabras con significados similares tienen representaciones similares.
La magia del Transformer: atención y arquitectura neuronal
El corazón de un LLM moderno es el mecanismo de atención. Para entender mejor como funciona podemos imaginarlo de la siguiente forma: cada palabra en una frase ‘mira’ a las demás para entender cuál es relevante para su contexto. Esto se logra mediante vectores llamados queries, keys y values, que permiten ponderar la influencia de cada palabra en la generación del siguiente token.
Elementos clave:
Query (Q): Vector que representa lo que buscamos.
Key (K): Vector que representa cada posible referencia.
Value (V): Vector con la información a extraer.
Aca nos vamos a poner un poco mas “Matemáticos”, pero es necesario que entendemos como interactúan cada uno de los factores en juego para el calculo de la atención, dado que logra simular en gran medida como los humanos asignamos la atención a las palabras dentro de nuestro lenguaje.
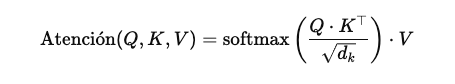


Parte I: Como realmente funcionan los tu IA favorita?
Cada vez que alguien me pregunta cómo funcionan modelos como ChatGPT, siento que detrás de una respuesta simple hay un universo entero de procesos matemáticos, lingüísticos y computacionales. Quiero contarte, de forma amena pero rigurosa, cómo funcionan los llamados Grandes Modelos de Lenguaje (LLM), y por qué han revolucionado la forma en que conectamos con la inteligencia artificial.
¿Qué es un LLM y qué lo hace tan especial?
Los LLM son modelos de inteligencia artificial entrenados con enormes cantidades de texto para comprender y generar lenguaje natural. Modelos como GPT-4, Claude o Gemini han sido entrenados con billones de palabras, absorbiendo patrones, estilos, gramática y hechos. Pero más allá del tamaño este proceso no ocurre de forma mágica: hay un flujo estructurado de procesamiento que va desde el texto en crudo hasta su representación matemática y su posterior interpretación mediante redes neuronales.
1- Tokenización: partir el lenguaje en fragmentos comprensibles
El primer paso para que una máquina entienda el lenguaje es dividir el texto en tokens, que pueden ser palabras, subpalabras o incluso sílabas. Esto permite que el modelo procese frases complejas como una secuencia ordenada de fragmentos reconocibles.
Ejemplo simple:
Texto: “Hola mundo”
Tokenización por palabras: [“Hola”, “mundo”]
Tokenización por subpalabras (BPE): [“Ho”, “la”, “mun”, “do”]
Los LLM como GPT usan tokenizadores basados en algoritmos como Byte Pair Encoding (BPE) o SentencePiece para dividir el texto en fragmentos reutilizables. Esto permite manejar vocabularios más pequeños y representar de manera eficiente palabras raras o compuestas.
2-Vectorización y Embeddings
Una vez que el texto se convierte en tokens, estos deben representarse de forma numérica para que una máquina pueda procesarlos. Esta representación se llama vectorización. Existen varias formas de hacer esto, una de ellas es One-hot encoding: Consiste en representar cada token como un vector con un único 1 en la posición correspondiente al token en el vocabulario, y 0 en las demás.
Sin embargo esto lleva a algunos problemas:
Escalabilidad: Si el vocabulario tiene 50,000 tokens, cada vector tendrá 50,000 dimensiones lo que incrementa la complejidad computacional de forma exponencial.
Semántica: Este metodo complica mucho la creacion de semantica, lo que implica crear conexiones logicas entre las palabras.
Esto lleva a la necesidad de representaciones más densas y semánticamente informativas: los embeddings.
A este punto todo se va poniendo un poco mas movido. Empecemos por las definiciones: los embeddings son vectores densos y continuos que representan tokens en un espacio de menor dimensión, donde la proximidad entre vectores refleja similitud semántica, que significa esto? pues que los vectores con mayor cercania representan palabras con un significado asociado mas profundo, gracias a esto el modelo puede entender que ‘rey’ y ‘reina’ están más cerca entre sí que ‘rey’ y ‘silla’.
Los embeddings se entrenan junto con el modelo. Inicialmente se asignan aleatoriamente y, a medida que el modelo aprende, se ajustan para que reflejen el contexto y significado de los tokens.
Cuales son las ventajas del uso de embeddings?
1-Capturan relaciones sintácticas y semánticas.
2-Permiten generalización: palabras con significados similares tienen representaciones similares.
La magia del Transformer: atención y arquitectura neuronal
El corazón de un LLM moderno es el mecanismo de atención. Para entender mejor como funciona podemos imaginarlo de la siguiente forma: cada palabra en una frase ‘mira’ a las demás para entender cuál es relevante para su contexto. Esto se logra mediante vectores llamados queries, keys y values, que permiten ponderar la influencia de cada palabra en la generación del siguiente token.
Elementos clave:
Query (Q): Vector que representa lo que buscamos.
Key (K): Vector que representa cada posible referencia.
Value (V): Vector con la información a extraer.
Aca nos vamos a poner un poco mas “Matemáticos”, pero es necesario que entendemos como interactúan cada uno de los factores en juego para el calculo de la atención, dado que logra simular en gran medida como los humanos asignamos la atención a las palabras dentro de nuestro lenguaje.
